

L'API Portic
Documentation technique sur l'utilisation de l'API https://anr.portic.fr et code source dans Gitlab
Cet ensemble de visualisations permet d’explorer distinctement, mais avec le même type d’outil graphique, deux types de sources :
Une troisième partie de l’application est plus personnalisable en permettant à l’usager de charger son propre jeu données dans l‘interface d’exploration, que ce soit à partir d’un fichier statique ou d’un flux de données accessibles par API.

Le menu du bandeau supérieur permet d’accéder à tout moment à chacune de ces pages.

Concernant les sets de données relatifs aux congés du G5 et aux entrées de Marseille sur lesquels sont “branchées” les visualisations, ils proviennent du mécanisme d’exposition des données par API mis en place dans le cadre du projet Portic.
Documentation technique sur l'utilisation de l'API https://anr.portic.fr et code source dans Gitlab
Par exemple, la requête utilisée pour obtenir les données des trajets relatifs à la source G5 est construite avec les paramètres suivants :
http://data.portic.fr/api/travels/?params=distance_dep_dest,departure_uhgs_id,departure_admiralty,departure_province,departure_states,departure_action,outdate_fixed,destination,destination_uhgs_id,destination_admiralty,destination_province,destination_states,destination_action,tonnage,tonnage_unit,flag,homeport,homeport_uhgs_id,homeport_admiralty,homeport_province,homeport_states,source_suite,homeport_uncertainity&format=csv
Chacun de deux corpus de données (G5 et Marseille) sont visualisables, de manière distincte mais homogène, au travers de deux types de vues.

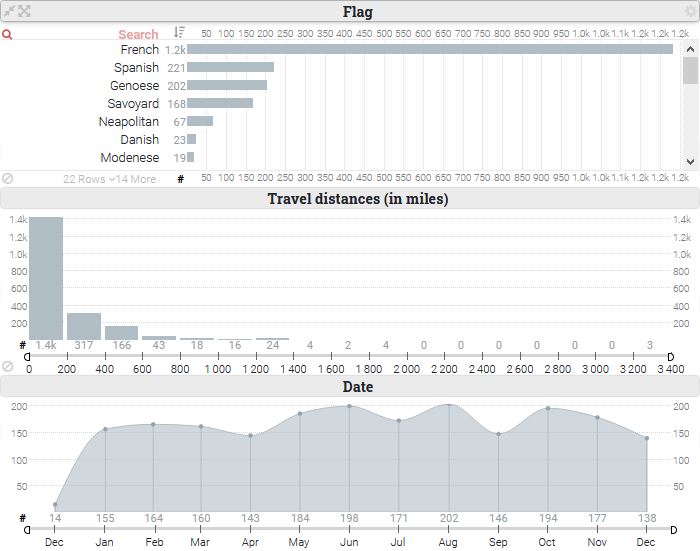
Les variables représentées sont agrégées dans des widgets (blocs) dédiés qui sont autant de points d’entrées dans le jeu de données :
Toutes les possibilités d’interactions utilisateur avec les données et de combinaisons de critères d’exploration sont présentées plus loin

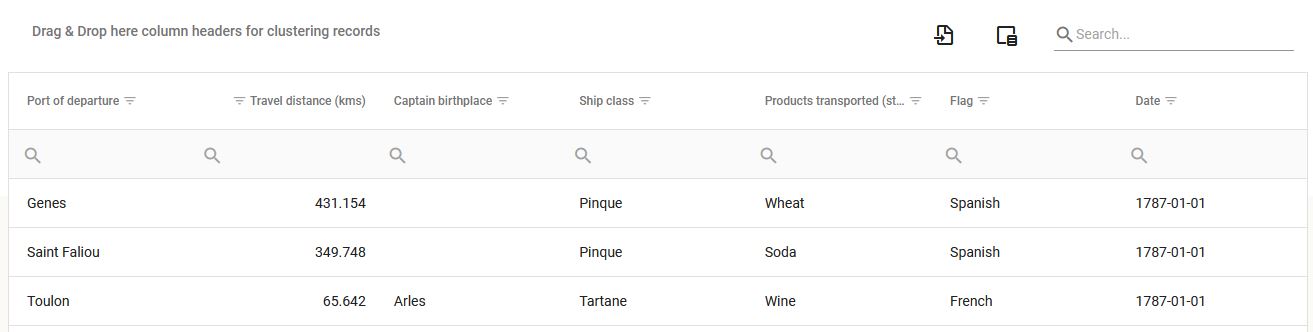
le même set de données est également accessible sous forme de tableau, une ligne par trajet et chaque variable en colonne. Les fonctionnalités associées au tableau en ligne permettent de trier, filtrer, regrouper, chercher dans et exporter les données (l’ensemble du set ou un sous-ensemble issu de manipulations effectuées dans l’affichage du tableau) en format Excel.
Toutes les possibilités d’interactions utilisateur avec les données et de combinaisons de critères d’exploration sont détaillées plus loin
Se reporter aux paragraphes sur la synchronisation des filtres et le constructeur de filtres
L’interface exploratoire présentant les données du G5 se lit de gauche à droite afin de présenter les trajets : à gauche sont explicitées les variables liées au départ (port d’attache, port de départ etc.), au centre les données analysées (tonnage, date de départ etc.) et à droite les destinations.
La présentation des données des registres du Bureau de la Santé se présentent également de gauche à droite. A gauche les informations liées au départ du navire, au centre les données générales sur le voyage (date de départ, nationalité etc.) et enfin à droite les informations liées au bateau : nationalité du capitaine, classe de bateau et produit transportés.
La description des trajets peut s’envisager à différents niveaux géographiques : port, province, amirauté et état. On retrouve donc cette approche multi-scalaire au niveau des variables décrivant les lieux d’attache du navire ainsi que les points de départ et de destination des trajets.
Port of registry : Port d’attache [G5]
Admiralty of registry : amirauté d’appartenance [G5]
Province of registry : province d’appartenance [G5]
State of registry : état d’appartenance [G5]
Port of departure : Port de départ [G5, Marseille]
Admiralty of departure : amirauté de départ [G5, Marseille]
Province of departure : province de départ [G5, Marseille]
State of departure : état de départ [G5, Marseille]
Port of destination : port de destination [G5]
Admiralty of destination : amirauté d’arrivée [G5]
Province of destination : province d’arrivée [G5]
State of destination : état d’arrivée [G5]
Flag : pavillon [G5, Marseille]
Burthen (en tonneaux) : contenance en tonneaux [G5, Marseille]
Burthen class (en tonneaux) : tonnages regroupés en intervalles de valeurs
Captain birthplace : Nationalité du capitaine [Marseille]
Ship class : type de bateau (frégate, brigantin etc.) [Marseille]
Products transported : marchandises transportées [Marseille]
Date : date de départ pour l’année 1789 (format yyyy-mm-dd) [G5, Marseille]
Homeport uncertainty : incertitude du port d’attache (valeurs 0, -1, -2 ou -3) [Marseille]
Travel distances : distance (en kms à vol d’oiseau) entre le port de départ et le port d’arrivée [G5, Marseille]
Sur les sources historiques, les méthodologies de traitement de l'incertitude, ainsi que sur la base de données
Au survol avec la souris de chaque modalité ou valeur affichée dans les blocs de variables, l’interface s’adapte de plusieurs manières :


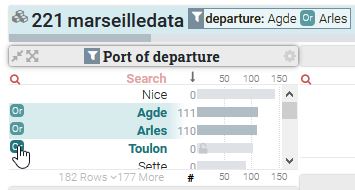
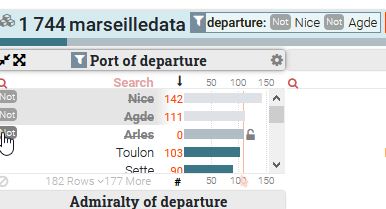
Le filtre peut aussi être inversement appliqué par exclusion de la valeur survolée, en survolant avec la souris l’icône Not s’affichant à gauche de chaque valeur.

Si vous souhaitez “réellement” filtrer” le dataset et n’afficher que certaines données, il vous suffit de cliquer sur la valeur voulue pour activer les opérations de filtrage et ré-organiser l’affichage des données en conséquence. Les fonctionnalités qui n’étaient que simulées lors du survol des valeurs avec la souris sont alors réellement activées et tous les blocs de données sont retriés dynamiquement.

Pour sélectionner un intervalle de dates dans le graphique en aire spécifique à ce type de variable, vous pouvez cliquer sur un point de l’axe des abscisses, un point de la courbe ou directement dans l’aire sous la courbe.
L’intervalle proposé par défaut est le mois, mais il est possible de l’augmenter en “attrapant” avec la souris la borne supérieure ou inférieure du segment et en la déplaçant le long de l’axe des abscisses.

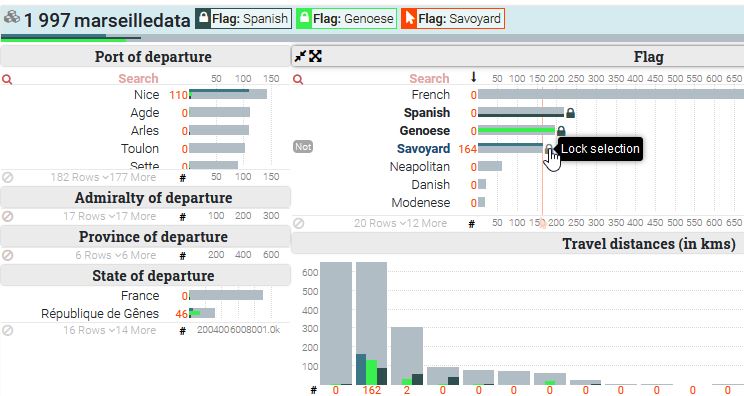
Si vous voulez visualiser la part relative de certaines valeurs dans chaque variable mais sans filtrer le dataset (en excluant celles qui ne remplissent pas la condition correspondant au filtre) ni re-trier l’ensemble du jeu de données, vous pouvez bloquer un filtre en cliquant sur l’icône Lock qui s’affiche à droite des valeurs au survol de la souris. La proportion de trajets pour chaque variable s’affichera en surbrillance mais sans réorganisation de l’interface.
Dans chaque widget de variable se trouve une icône « search » symbolisée par une loupe. Cet espace vous permet de saisir la donnée que vous souhaitez afficher. La liste des valeurs se met à jour au fur et à mesure de la saisie du texte dans la barre de recherche.

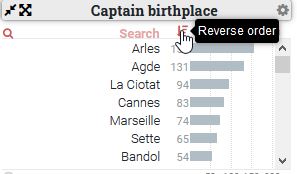
Au sein de chaque widget, les données sont triées par ordre décroissant de valeurs, néanmoins il est possible d’inverser l’ordre des données grâce à l’icône de tri (qui ne s’affiche que lorsque la souris de l’utilisateur passe sur le widget et se place à droite de l’icône de recherche).
La vue d’exploration ne propose pas de fonctionnalités d’export des données, et fournit seulement une vision du dataset au travers de données agrégées dans l’interface. Afin de pouvoir accéder au détail des trajets et/ou d’exporter les données, il faut se reporter à la vue en tableau du même jeu de données.
De plus, si vous souhaitez voir et exporter les données non agrégées correspondant à l’état de la vue exploratoire auquel vous êtes parvenus après avoir actionné des filtres, il suffit de sélectionner l’option “Synchroniser les filtres avec la vue en tableau”. La combinaison de filtres appliquée dans la visualisation graphique est alors traduite en requête pour le constructeur de filtres associé au tableau de données, le filtre sera alors automatiquement appliqué sur le tableau.

Vous pouvez désactiver la synchronisation des filtres auquel cas les manipulations effectuées dans l’interface d’exploration ne sont pas reportées dans la vue tabulaire (comportement par défaut)
Cette fonctionnalité permet de modifier les variables présentées par défaut dans l’interface. En sélectionnant l’écrou  en haut à droite de la visualisation, vous pourrez ajouter ou supprimer des variables contenues dans la base de données et ainsi organiser l’interface en fonction de vos besoins.
en haut à droite de la visualisation, vous pourrez ajouter ou supprimer des variables contenues dans la base de données et ainsi organiser l’interface en fonction de vos besoins.
En cliquant sur l’écrou la section d’exploration se divise en deux parties avec dans le bandeau gauche une liste de blocs représentant chaque variable : chaque bloc affiche une synthèse des données (nombre de valeurs uniques et diagramme en barres horizontales) et offre la possibilité de renommer la variable pour un affichage personnalisé.
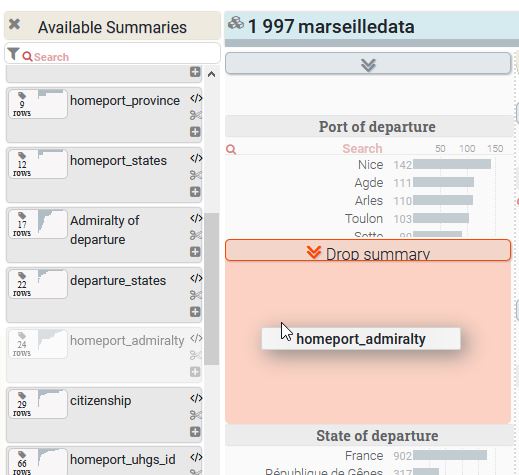
Pour intégrer un bloc dans l’interface sous forme de widget, il suffit de le déplacer avec la souris en glisser-déposer du bandeau gauche jusqu’à l’emplacement souhaité
Enfin, dans la partie principale de l’écran, il devient possible de supprimer un widget en cliquant sur la croix à gauche dans le bandeau d’en-tête du widget.

Il est possible d’agrandir la visualisation afin de la mettre en plein écran avec le bouton Fullscreen  en haut à droite de l’interface.
en haut à droite de l’interface.
Dans la même démarche, chaque widget peut être réduit ou agrandi grâce aux icônes présentes sur la gauche dans le bandeau du titre. Celles-ci s’affichent au survol du widget par la souris (d'ailleurs certaines variables sont déjà réduites par défaut afin de faciliter la compréhension des données).

Dans chaque widget il est possible de régler la taille des caractères grâce à l’écrou s’affichant à droite du titre de chaque widget. Visible au survol de la souris, il permet d’afficher les options de configuration disponibles.

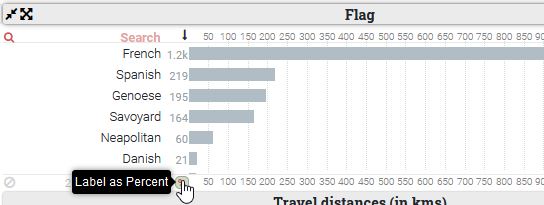
Il est possible de passer d’un affichage des données en valeurs absolues par défaut à un affichage en valeurs relatives en cliquant sur le symbole # présent au début des valeurs en abscisses de chaque graphique, qui active l’option de modification des valeurs en pourcentage.

A venir...
Cette vue expose les données, non plus de manière agrégée, mais au niveau de chaque trajet dans un tableau modifiable en ligne.
Par défaut les résultats en tableau sont paginés par lots de 10, et l’option de navigation dans les pages de résultats se trouve en dessous des lignes de données. Sur la gauche du pied-de-page du tableau se trouve également la possibilité d’augmenter le nombre de résultats rendus par page.

En pied-de-page se trouve également une ligne de données indiquant (dynamiquement en fonction des filtres activés) le nombre total de lignes du tableau, les valeurs minimales et maximales de tonnage (G5), les valeurs minimales et maximales de distance entre point de départ et d’arrivée du navire.

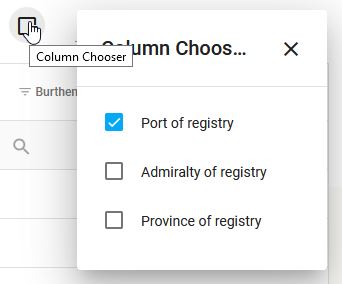
Le bouton  dans la barre supérieure du tableau permet de sélectionner les colonnes à afficher ou masquer sur la page web (pour plus de lisibilité, certaines sont d’ailleurs masquées par défaut).
dans la barre supérieure du tableau permet de sélectionner les colonnes à afficher ou masquer sur la page web (pour plus de lisibilité, certaines sont d’ailleurs masquées par défaut).
L’agencement des colonnes peut être modifié par simple glisser-déposer des en-têtes de colonnes avec la souris.
Le bouton  dans la barre supérieure du tableau permet d’exporter les données en format Excel.
dans la barre supérieure du tableau permet d’exporter les données en format Excel.
Attention, les données exportées correspondent à l’état du tableau tel qu’affiché au moment de l’export.
Le tri ascendant ou descendant de l’ensemble des données en fonction d’une variable s’effectue en cliquant sur l’ en-tête de la colonne correspondante. Il est bien sûr possible de combiner successivement plusieurs critères de tri.
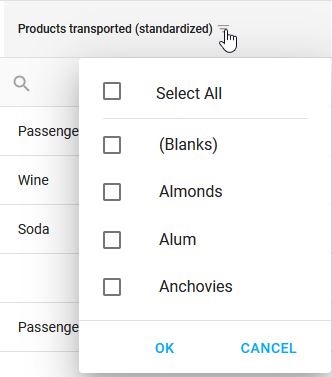
En cliquant sur l’icône de filtre à droite du nom de chaque colonne, une popup affiche les valeurs uniques de la variable dans une liste permettant d’en sélectionner une ou plusieurs en tant que filtre sur les données.
Sous chaque en-tête de colonne, une barre de recherche permet de saisir du texte libre à rechercher dans les valeurs de la variable, et d’associer un opérateur à la requête (de type contains, not contains, equals, starts with, ends with…). Les opérateurs disponibles sont contextuels au type (quantitatif, qualitatif, date) de la variable.
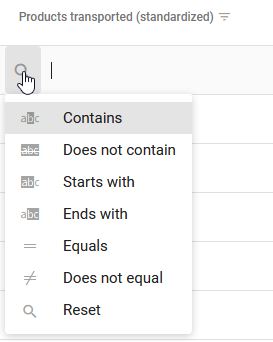
La barre de recherche placée au-dessus et sur la droite du tableau permet la saisie de texte libre et la recherche sur l’ensemble de jeu de données, les données sont alors filtrées dynamiquement au fur et à mesure de la saisie et la suite de caractères recherchée mise en surbrillance dans les résultats.

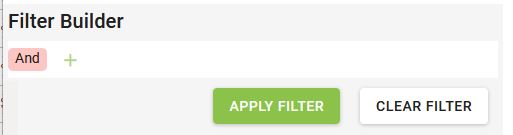
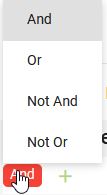
Dans la partie supérieure de l’écran au-dessus du tableau se trouve un bloc spécifique dédié à la construction de requêtes de filtrage avancées, qui permet de créer plusieurs filtres et de les combiner entre eux par les opérateurs booléens AND, OR, NOT AND, NOT OR.
Les filtres à appliquer peuvent s’enchaîner successivement les uns aux autres ou être logiquement regroupés en groupes de conditions.
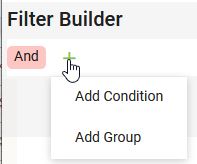
Il suffit de cliquer sur l’icône  pour ajouter un nouveau filtre et la saisie des requêtes est simplifiée grâce à l’affichage dynamique de la variable à sélectionner et de l’opérateur à appliquer.
pour ajouter un nouveau filtre et la saisie des requêtes est simplifiée grâce à l’affichage dynamique de la variable à sélectionner et de l’opérateur à appliquer.

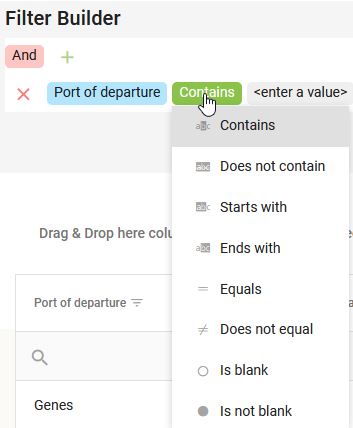
Enfin, comme pour l’option de filtrage située au niveau de chaque colonne, les opérateurs proposés pour construire le filtre différent selon que la variable soit une catégorie, un nombre ou une date.
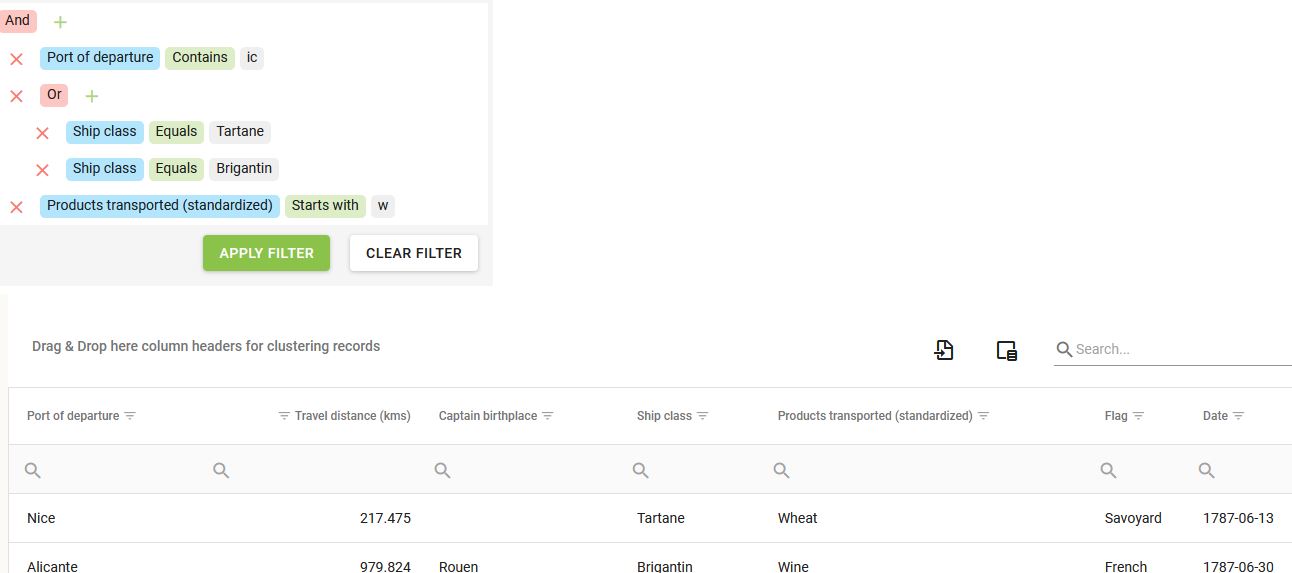
Voici par exemple la construction logique du filtre et les résultats correspondant à la requête suivante sur les données des entrées de Marseille en 1787 : “je cherche tous les bateaux de type Tartane ou Brigantin partis d’un port dont le nom contient les lettres ‘ic’ et qui transportaient une marchandise dont le nom commence par W”
Si l’option “Synchroniser les filtres avec la vue en tableau” est sélectionnée dans la vue exploratoire en widgets, les filtres appliqués dans cette première visualisation sont “traduits” et reportés dans le constructeur de filtres de la vue en tableau.
Cette fonctionnalité permet de passer de la manipulation des trajets à un niveau agrégé à une liste plus précise trajet par trajet, ainsi qu’aux autres fonctionnalités disponibles dans la vue tabulaire (possibilité d’export notamment).
Les données de trajet peuvent faire l’objet de regroupement par valeurs au sein du tableau par un simple glisser-déposer de l’en-tête de la colonne souhaitée comme critère de clusterisation dans la partie supérieure gauche du tableau (symétriquement l’opération inverse de retour aux données plates s’effectue par re-déplacement de la variable dans la première ligne des en-têtes de colonnes).

Les lignes de trajets se partitionnent alors en sous-groupes (dépliables et repliables) en fonction des valeurs de la variable choisie.

L’utilisateur peut cumuler les regroupements par glisser-déposer successif de chaque colonne souhaitée, les données s’organisent alors selon une arborescence de sous-groupes en fonction de l’ordre de réalisation de l’opération.
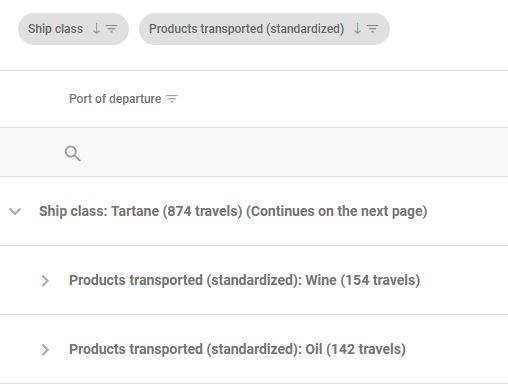
Les mêmes options de tri par ordre croissant/décroissant et de sélection de valeurs dans la variable choisie sont actionnables.
A venir...
L’application offre aussi la possibilité d’intégrer, visualiser et interagir avec vos données en utilisant la vue d’exploration interactive.
Les possiblités d'import sont de deux types.
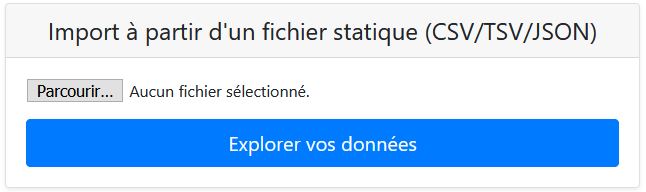
Cliquer sur "Parcourir" pour récupérer le fichier de données à son emplacement sur le PC, puis sur "Explorer vos données" pour les charger dans l’interface.
Les fichiers plats csv et tsv doivent comporter des en-têtes de colonnes.
Pour les fichiers csv, le séparateur doit être le point-virgule ;
Les fichiers json doivent présenter une arborescence simple à un niveau de tableau peuplés d'objets, par exemple
[{"travel_rank":1,
"ship_id":"0000001N",
"departure":"Boulogne sur Mer",
"destination":"Angleterre",
"departure_action":"Out"},
{...},
...]
Il suffit alors de rentrer dans le champ texte l’url externe servant de point d’accès aux données qui doivent être formatées en Json simple. Par exemple si on utilise l’API Portic /flows comme source de données afin d’obtenir tous les trajets sortants (dédoublonnées) liés à Boulogne/Mer pour l’année 1787 avec certains paramètres :
http://data.portic.fr/api/flows/?format=json&ports=A0152606°ree=1&direction=Out¶ms=travel_rank,ship_id,departure,destination,departure_action,destination_action,distance_dep_dest,travel_uncertainity&both_to=false
Le bouton  permet de vérifier la validité de l’url, l'accès aux données par le client web, et la conformité des données.
permet de vérifier la validité de l’url, l'accès aux données par le client web, et la conformité des données.
En cliquant sur “Explorer vos données”, l’application interroge donc l’url saisie, parse les données et les charge dans la visualisation.
Une fois les données source lues et parsées, les variables sont identifiées par l’application (les en-têtes de colonnes pour les fichiers csv, les clés des objets pour les formats Json) et sont affichées en blocs distincts dans la colonne de gauche de l’écran.
L’utilisateur peut ainsi construire sa visualisation personnalisée en disposant les widgets comme il le souhaite dans la partie centrale de l’écran par un simple glisser-déposer des blocs de variables, comme expliqué plus haut

Le bouton en haut à droite de la visualisation permet d’afficher/masquer la colonne des variables.
A venir...
Tout comme l’ensemble des développements réalisés dans le cadre du projet Portic, le code de l’application est disponible en open source sur le dépôt Gitlab de l’équipe Portic hébergé par la TGIR Human-Num